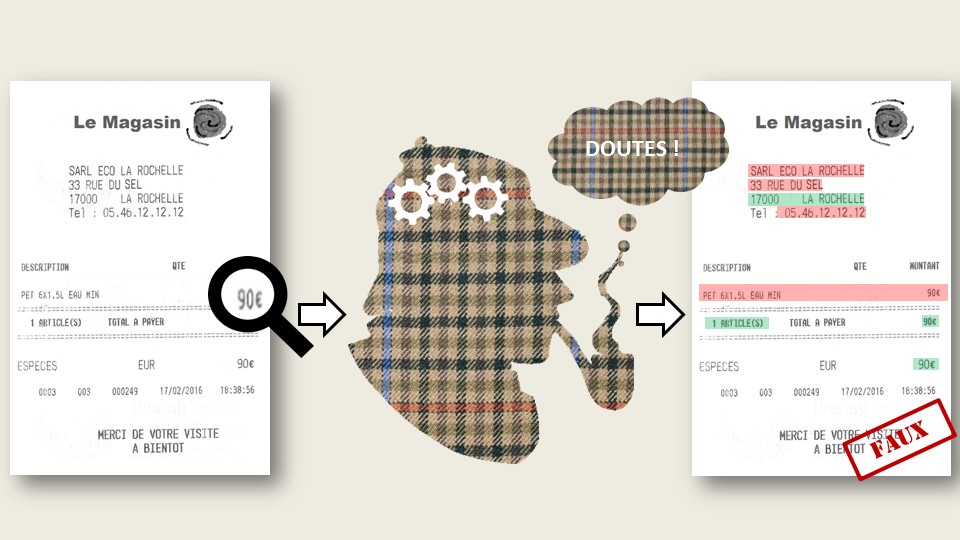
We propose two contest tasks, that can be performed with methods based on the image, on the text or either, depending on the choice of participants. These tasks are :
- The detection of the falsified documents among others. The provided dataset will contain both genuine and modified documents. The first task aims at discovering which ones are forged.
- The spotting of this falsification in the document (many falsifications can occur in one document). The aim of the contest is to collect a maximum of methods to be compared. To follow this idea, we suggest that the contest may be opened to two communities :
- People working at image level : disruption in fonts, localisation of visual anomalies, default of texture, etc..
- People working at text level to discover inconsistencies in association rules (abnormal price for a topic), errors in cumulative sums, information checking, etc…